

Apache Kafka


Apache Kafka is a powerful distributed event streaming platform, offering high-throughput, fault-tolerance, and scalability for real-time data processing. Let's have a look at Apache Kafka Architecture:
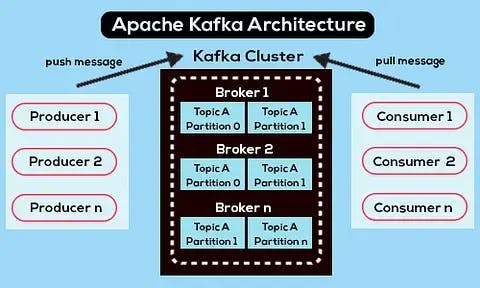
Here are key points to keep in mind when exploring Apache Kafka:
1. Publish-Subscribe Model
- Kafka operates on a publish-subscribe model, where producers publish messages to designated topics, and consumers subscribe to those topics to receive and process the messages. This decoupling of producers and consumers allows for a flexible and scalable architecture.
2. Distributed and Fault-Tolerant
- Kafka's architecture is designed to be distributed across multiple nodes, called brokers. This distribution ensures fault tolerance by partitioning data across brokers, and each partition is replicated. Even if some nodes fail, the system remains operational.
3. High Throughput
- The platform is optimized for high throughput, enabling it to handle a massive volume of data streams efficiently. This feature is essential for real-time data processing and analytics, making Kafka a go-to solution for scenarios with demanding workloads.
4. Durability
- Kafka ensures data durability by replicating data across multiple brokers. This replication mechanism guarantees that even if a broker fails, data is not lost, maintaining a high level of reliability in data storage and retrieval.
5. Scalability
- Kafka's architecture allows for horizontal scalability. You can easily scale the system by adding more brokers to the cluster. This flexibility enables Kafka to adapt to changing workloads and evolving data requirements.
6. Retention
- Kafka allows the retention of data for a specified period. This feature is valuable for both real-time and historical analysis, offering organizations the ability to revisit and analyze past data points for various purposes.
7. Connectivity
- Kafka Connect is a framework that simplifies integration with various data sources and sinks. This facilitates seamless data movement between Kafka and other systems, making it a versatile tool for connecting different components of a data ecosystem.
8. Streaming Processing
- Kafka's Streams API enables the development of real-time applications and microservices. This API allows developers to process and analyze data in motion, opening the door to a wide range of real-time use cases, from fraud detection to personalized recommendations.